



新闻动态
联系方式
联系人:辜渝傧
联系电话:13037102709
公司电话:027-87870986
公司地址:湖北省武汉市东湖新技术开发区金融港四路中原电子民品园10号楼

大数据技术区||Hadoop的生态系统
目前Hadoop已经发展成为包含很多项目的集合,形成了一个以Hadoop为中心的生态系统,Hadoop1.0代生态系统各层结构如图2-2所示,Hadoop2.0代生态系统各层结构如图2-3所示。
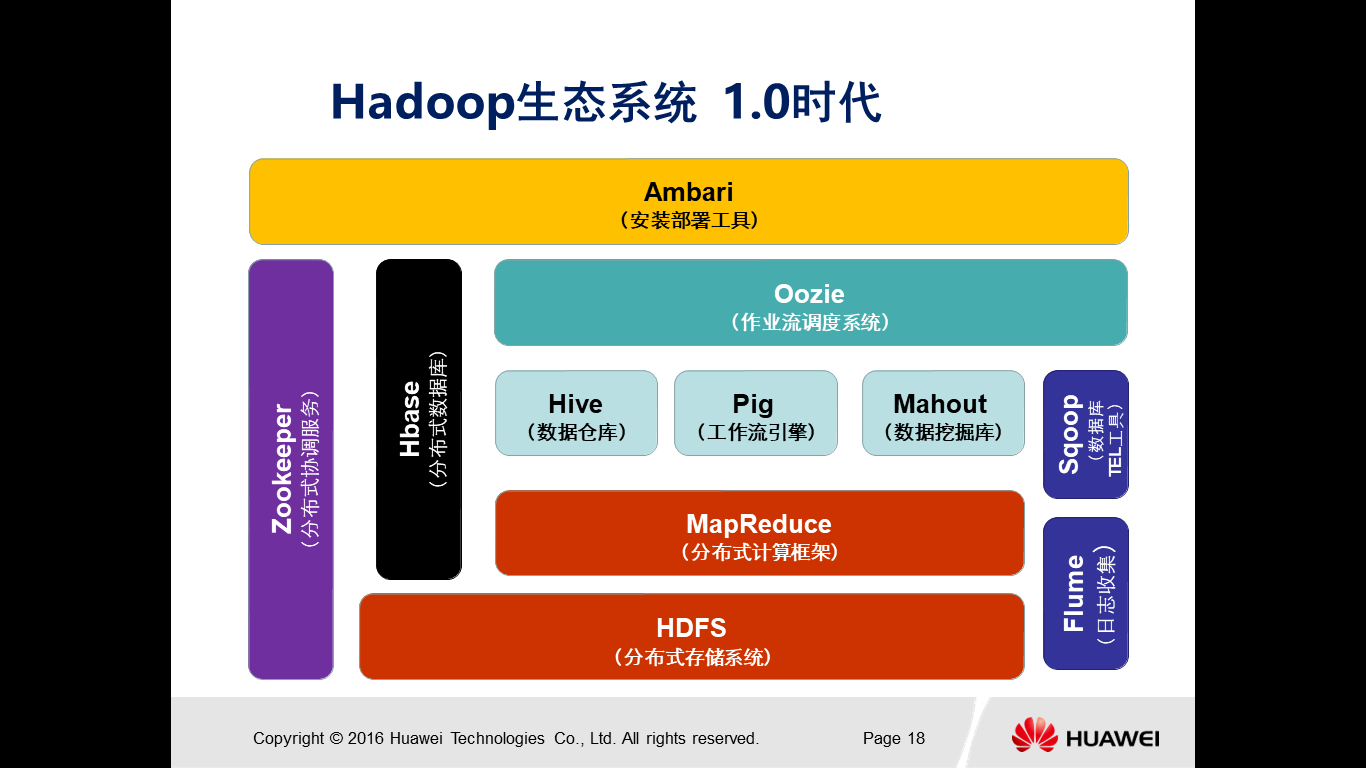
图2-2 Hadoop1.0代的生态系统
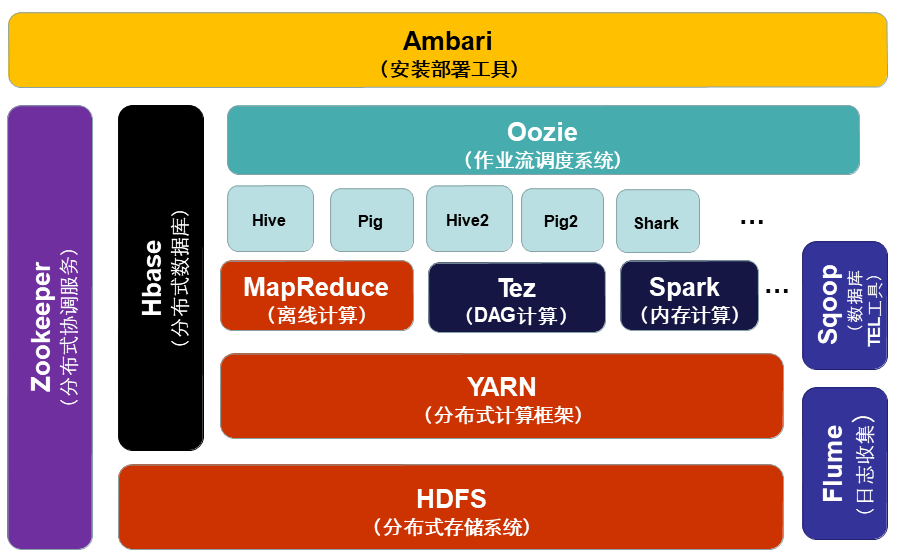
图2-3 Hadoop2.0代的生态系统
Hadoop的核心组件的Logo如图2-4所示,功能简介如下。
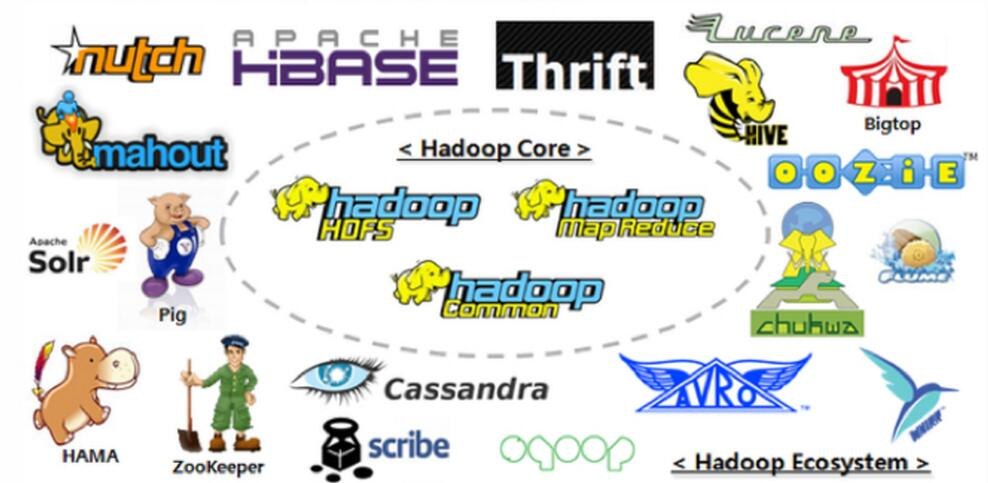
图2-4 Hadoop核心组件的Logo
Hadoop Common:Hadoop核心组件,其他所有组件都依赖它。
HDFS:分布式文件存储系统。
YARN:资源管理系统,用于管理计算资源和调度用户作业。
MapReduce:大数据分布式处理框架。
Hive:Facebook贡献的分布式数据仓库,用于数据统计、查询和分析,提供 SQL 接口。Hive管理存储在HDFS中的数据,提供了基于SQL的查询语言(由运行时的引擎翻译成MapReduce作业)查询数据。
HBase:分布式列数据库,用于快速存取。
Zookeeper:用于构建分布式应用,提供类似Google Chubby的功能,主要用于解决分布式一致性问题。
Oozie:工作流调度系统,用于定义一系列工作流以及执行路径。
Sqoop:ETL工具,用于在Hadoop和关系型数据库之间做数据转移。
Flume:Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume也提供对数据进行简单处理,并写到各种数据接受方的能力。
Pig:分布式数据分析工具,是数据处理脚本,提供相应的数据流(Data Flow)语言和运行环境,实现数据转换和实验性研究,适用于数据准备阶段。
Mahout:机器学习和数据挖掘的一个分布式框架,区别于其他的开源数据挖掘软件,它基于Hadoop之上,用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题,所以Hadoop的优势就是Mahout的优势。
BI Reporting:商业智能报表,能提供综合报告、数据分析和数据集成等功能。
Spark:基于内存的数据分析、挖掘和建模框架。
Avro:一种新的数据序列化(serialization)格式和传输工具,主要用来取代Hadoop基本架构中原有的IPC机制。
Ambari:一种基于Web的工具,可帮助系统管理员部署和配置Hadoop、升级集群以及监控服务。支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理,是5个顶级hadoop管理工具之一。
唯众大数据实训平台助你快速掌握大数据关键技术点
大数据实训平台简介
唯众大数据实训平台系统是针对IT类实验室现状开发的一套虚拟化网络创新教学实训平台,它采用B/S的软件架构,基于web浏览器访问,以少量硬件设备完成大量实训集群的构建,可提供大量学生进行IT类相关实训。每个学生的实训环境互相隔离、实训过程互不干扰。同一页面中既包含了各类实操环境,也包含了每个实验对应的实验文档,省去了在同页面间来回切换的麻烦,实验过程采用分布式设计,配合大数据分析模块,实时监控每个步骤的学习情况,方便学生高效的完成实训操作的同时,大幅节省了硬件成本和人力成本的投入。
大数据实训平台特点
配置灵活- 支持集群部署,支持集群内管理云主机,提供高可用特性,自动生成IP池,内置DHCP服务器,自动为云主机分配IP地址
- 支持自定义镜像上传,可满足多种格式镜像上传及管理功能
- 支持批量创建/删除多个云主机,支持云主机基本生命周期控制,
- 支持自定义云主机配置管理
操作简便
- 同一页面中既包含了各类实操环境,也包含了每个实验对应的实验文档,省去了在同页面间来 回切换的麻烦。
- 学生在实验过程中可以根据学习内容记录学习笔记,并查看他人笔记
- 学生在实验过程中可以将自己遇到的问题进行提问或回答其他同学的问题,老师或其他同学可对起问题进行回答
- 学生在实验结束后在线提交实验报告,并查看成绩以及评语
大数据实训资源
大数据之Linux基础
大数据之Python基础
大数据之MySQL基础
大数据之Java程序设计
大数据之jQuery数据处理
大数据之可视化
大数据之JavaWeb应用程序设计
大数据之JavaWeb图书管理系统项目
大数据之JavaWeb试题库管理系统项目
大数据之环境搭建
Hadoop离线大数据网站点击流日志分析
Hadoop离线大数据学情分析系统开发
Spark Streming医疗实时审核系统开发
Spark用户人群画像系统开发
